
|
|
|


 ~ May. 2017 ~
~ May. 2017 ~ 








|

|
|
|

|
|
I'm interested in various topics in robotics, machine learning and computer vision. Here is the list of my selected publications. For the complete list of my publications please visit my Google Scholar page and DBLP. |
|
|
|
|
Fereshteh Sadeghi Ph.D. Dissertation, University of Washington, Computer Science, 2019 |
|
|
 |
arXiv preprint arXiv:2203.17138 , 2022 We present an approach built upon previous work on imitating human or dog Motion Capture (MoCap) data to use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach does not require extensive reward engineering to produce sensible and natural looking behavior which enables skill reuse suitable for creating well-regularized, task-oriented controllers for real locomotive robots. We demonstrate how our approach can imitate human and animal natural movement and learn controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. |
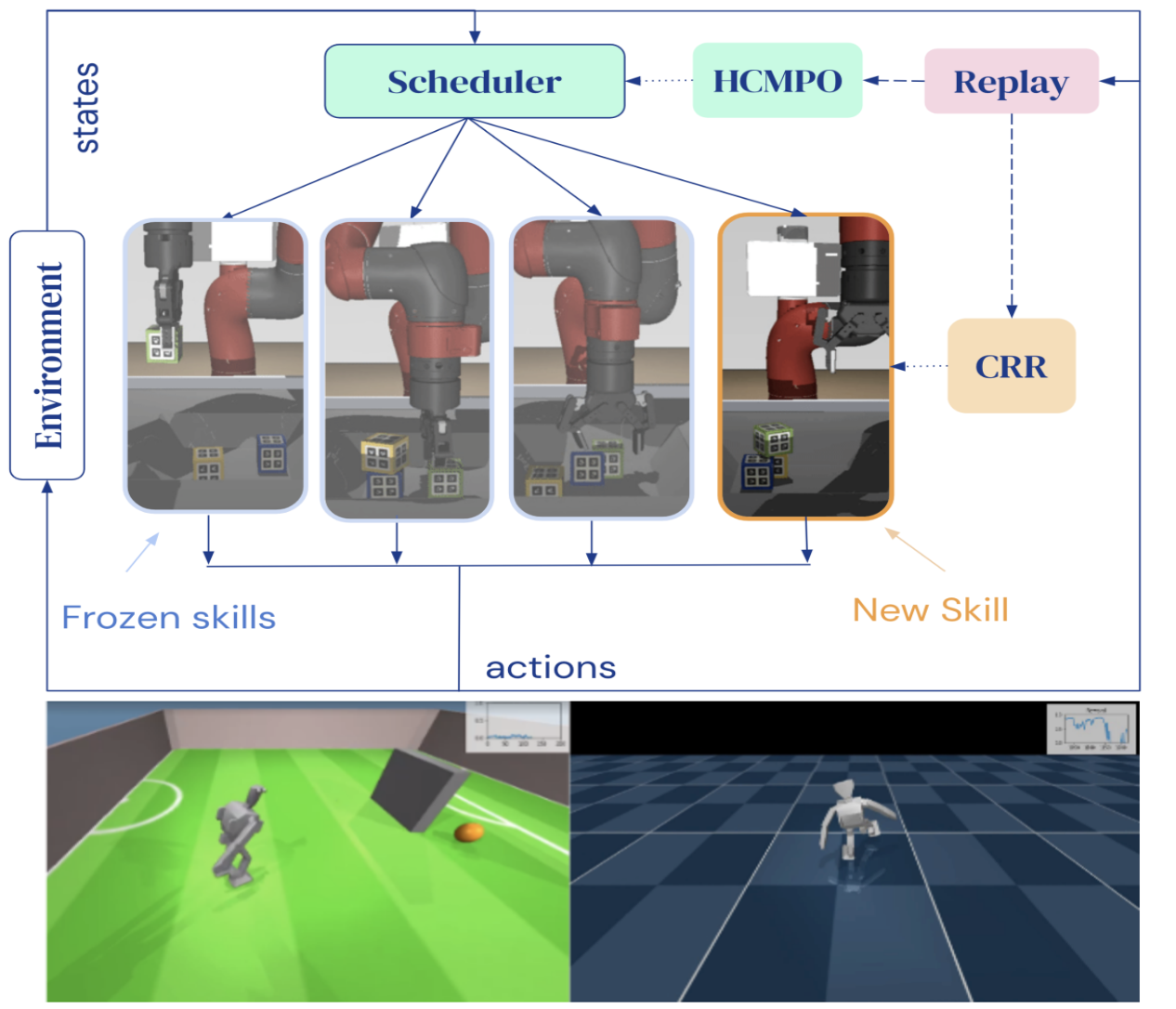 |
arXiv preprint arXiv:2211.13743 , 2022 We present an adaptive skill sequencing approach to learn temporally extended tasks on multiple domains including changes in task and system dynamics. Our approach learns to sequence existing temporally-extended skills for exploration but learns the final policy directly from the raw experience. We compare against many classical methods use a broad set of ablations to highlight the importance of different components of our method. |
 |
arXiv preprint arXiv:1908.08031 , 2019 MuSHR is a low-cost, open-source robotic racecar platform for education and research. MuSHR aspires to contribute towards democratizing the field of robotics as a low-cost platform that can be built and deployed by following detailed, open documentation and do-it-yourself tutorials. |
|
|
 |
ICRA , 2023 We present a sim2real system with realistic visuals for learning active perception policies "in the wild". Using a video of a static scene collected using a generic phone, we learn the 3D model of the scene via Neural Radiance Field (NeRF) and we augment the NeRF rendering of the static scene by overlaying the rendering of other dynamic objects (e.g. the robot's own body, a ball) and use a physics simulator to learn a robot policy that relies on contact dynamics, static scene geometry and the dynamic objects' geometry and physical properties. We demonstrate that we can use this simulation to learn vision-based whole body navigation and ball pushing policies for a 20 degrees of freedom humanoid robot with an actuated head-mounted RGB camera, and we successfully transfer these policies to a real robot. |
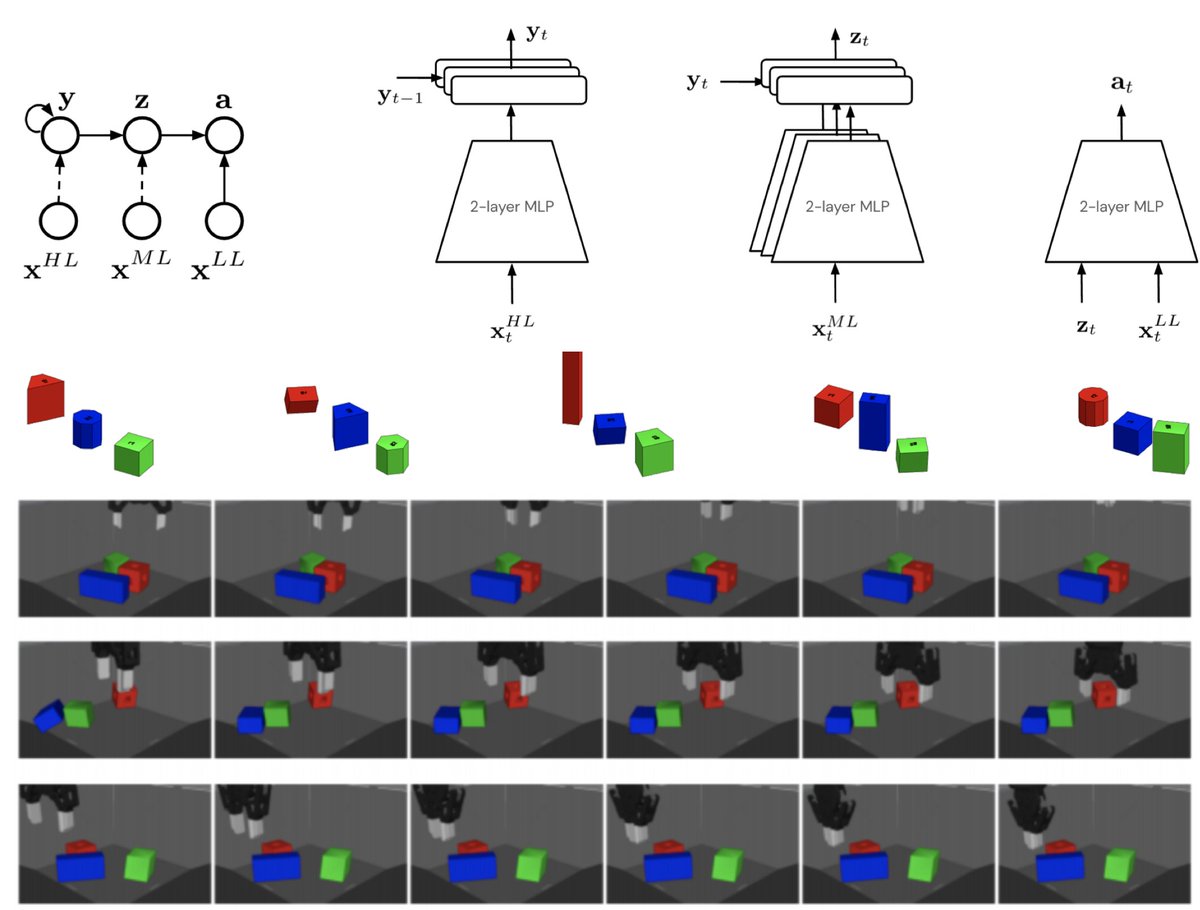 |
Spotlight ICLR, 2022 We present an approach that can learn reusable behaviours that can effectively be transferred and adapted to numerous tasks and scenarios. Our proposed method exploits a three-level hierarchy of both discrete and continuous latent variables, to capture a set of high-level behaviours while allowing for variance in how they are executed. We demonstrate in manipulation domains that the method can effectively cluster offline data into distinct, executable behaviours and the learned skills can be transferred and fine-tuned on new tasks, unseen objects, and from state to vision-based policies. |
 |
Fereshteh Sadeghi Robotics: Science and Systems (RSS), 2019 In this paper, we investigate how to minimize human effort and intervention to teach robots perform real world tasks that incorporate semantics and we propose DIViS, a Domain Invariant policy learning approach for collision free Visual Servoing. While DIViS does not use any real robot data at the training time it is capable of servoing real mobile robots to semantic object categories in many diverse and unstructured real-world environments. |
 |
Fereshteh Sadeghi Conference on Computer Vision and Pattern Recognition (CVPR), 2018 In this paper, we study how viewpoint-independent visual servoing skills can be learned automatically in a robotic manipulation scenario. To this end, we train a deep, recurrent controller that can automatically determine which actions move the end-point of a robotic arm to a desired object. We show how we can learn this recurrent controller using simulated data, and then describe how the resulting model can be transferred to a real-world Kuka IIWA robotic arm. |
 |
Fereshteh Sadeghi Robotics: Science and Systems (RSS), 2017 Neural Information Processing Systems (NeurIPS) DL for action and interaction workshop Spotlight, 2016 Neural Information Processing Systems (NeurIPS) DeepRL Workshop, 2016 We propose simulation randomization (a.k.a. Domain Randomization) for direct transfer of vision-based policies from simulation to the real world. CAD2RL is a flight controller for Collision Avoidance via Deep Reinforcement Learning that can be used to perform collision-free flight in the real world although it is entirely trained in a 3D CAD model simulator. Our method uses only single RGB images from a monocular camera mounted on the robot as the input and is specialized for indoor hallway following and obstacle avoidance. |
 |
Fereshteh Sadeghi Neural Information Processing Systems (NeurIPS), 2015 In this paper, we study the problem of answering visual analogy questions. These questions take the form of image A is to image B as image C is to what. Answering these questions entails discovering the mapping from image A to image B and then extending the mapping to image C and searching for the image D such that the relation from A to B holds for C to D. We pose this problem as learning an embedding that encourages pairs of analogous images with similar transformations to be close together using convolutional neural networks with a quadruple Siamese architecture. |
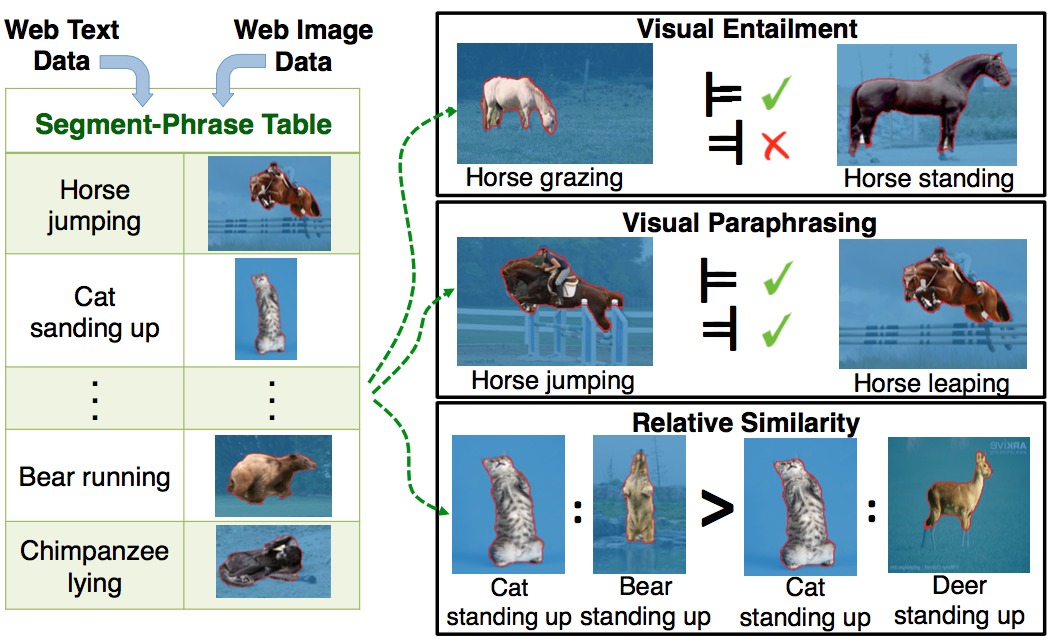 |
International Conference on Computer Vision (ICCV), Oral 2015 Segment-Phrase Table (SPT) is a large collection of bijective associations between textual phrases and their corresponding segmentations. We show that fine-grained textual labels facilitate contextual reasoning that helps in satisfying semantic constraints across image segments. This feature enables us to achieve state-of-the-art segmentation results on benchmark datasets. We also show that the association of high-quality segmentations to textual phrases aids in richer semantic understanding and reasoning of these textual phrases which motivates the problem of visual entailment and visual paraphrasing. |
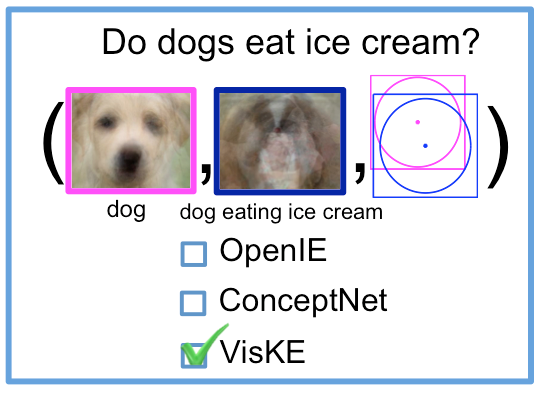 |
Fereshteh Sadeghi Conference on Computer Vision and Pattern Recognition (CVPR), 2015 In this work, we introduce the problem of visual verification of relation phrases and developed a Visual Knowledge Extraction system called VisKE. Given a verb-based relation phrase between common nouns, our approach assess its validity by jointly analyzing over text and images and reasoning about the spatial consistency of the relative configurations of the entities and the relation involved. Our approach involves no explicit human supervision thereby enabling large-scale analysis. Using our approach, we have already verified over 12000 relation phrases. Our approach has been used to not only enrich existing textual knowledge bases by improving their recall, but also augment open domain question-answer reasoning. |
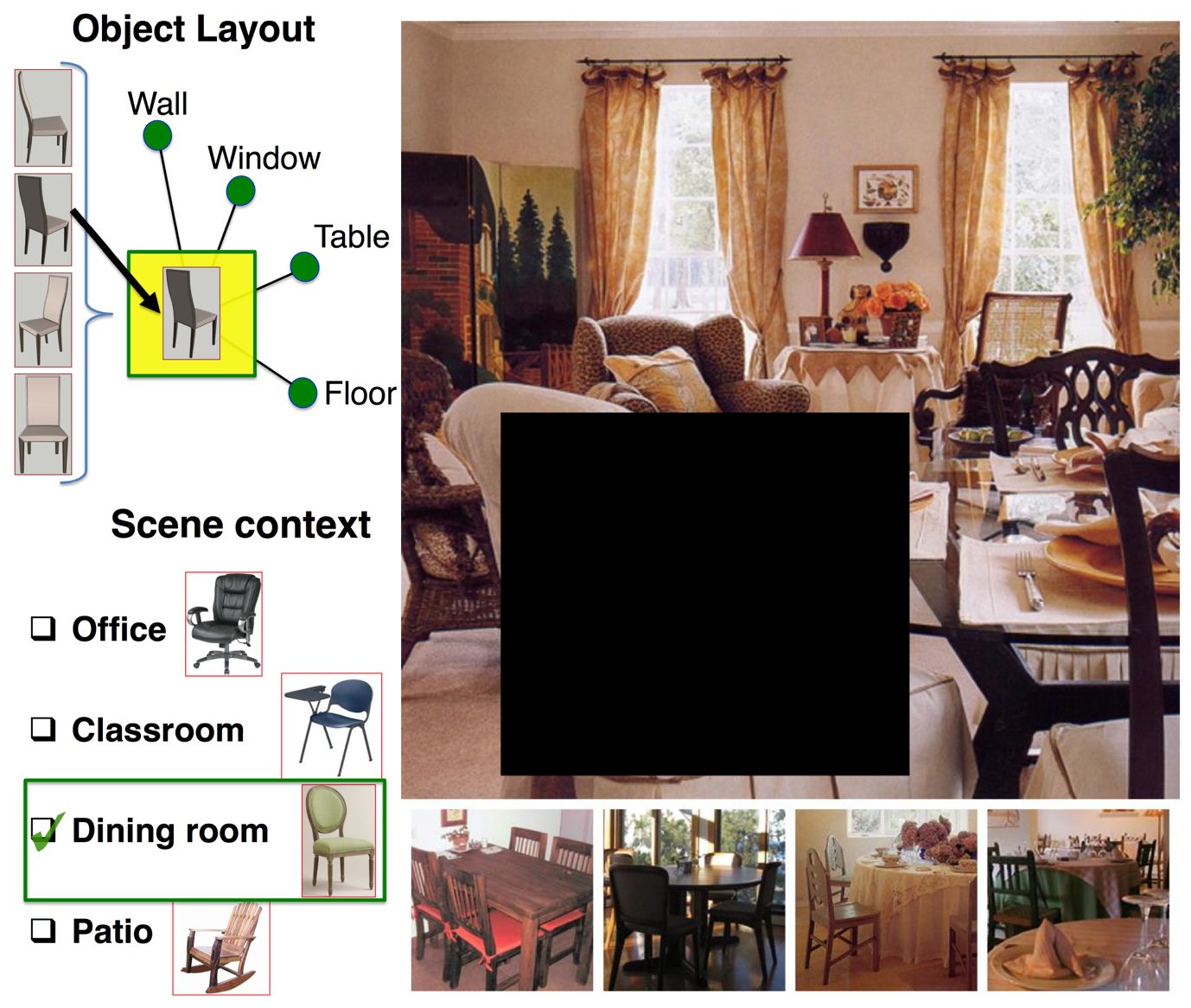 |
*: equal contibution Conference on Computer Vision and Pattern Recognition (CVPR), Spotlight 2014 In this paper, we propose a method to learn scene structures that can encode three main interlacing components of a scene: the scene category, the context-specific appearance of objects, and their layout. Our experimental evaluations show that our learned scene structures outperform state-of-the-art method of Deformable Part Models in detecting objects in a scene. Our scene structure provides a level of scene understanding that is amenable to deep visual inferences. The scene struc- tures can also generate features that can later be used for scene categorization. Using these features, we also show promising results on scene categorization. |
 |
Fereshteh Sadeghi Winter Conference on Applications of Computer Vision (WACV), 2015 we propose the problem of automatic photo album creation from an unordered image collection. To help solve this problem, we collect a new benchmark dataset based on Flicker images. We analyze the problem and provide experimental evidence, through user studies, that both selection and ordering of photos within an album is important for human observers. To capture and learn rules of album composition, we propose a discriminative structured model capable of encoding simple prefer ences for contextual layout of the scene and ordering between photos. The parameters of the model are learned using a structured SVM framework. |
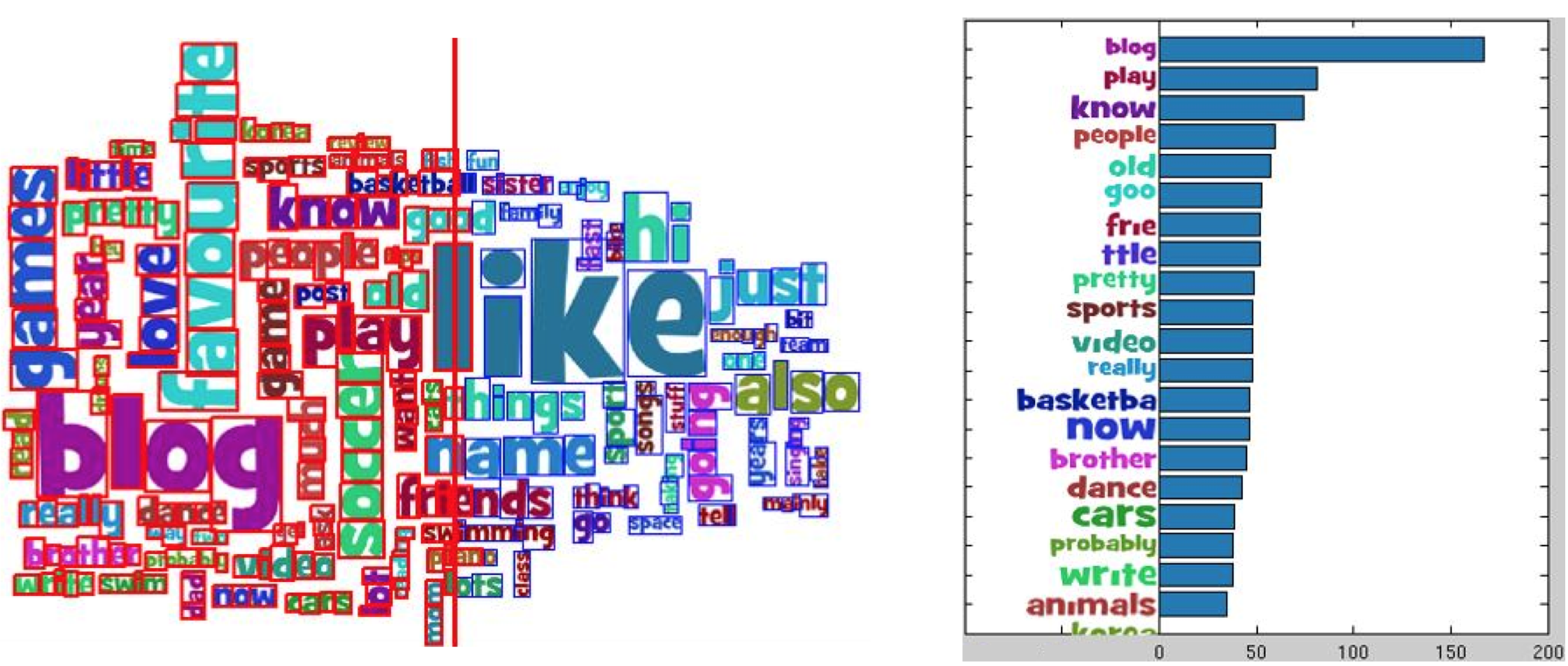 |
Fereshteh Sadeghi arXiv:1412.6079, 2014 Despite the attractiveness and simplicity of producing word clouds, they do not provide a thorough visualization for the distribution of the underlying data. Our proposed method is able to decode an input word cloud visualization and provides the raw data in the form of a list of (word, value) pairs. To the best of our knowledge our work is the first attempt to extract raw data from word cloud visualization. The results of our experiments show that our algorithm is able to extract the words and their weights effectively with considrerable low error rate. |
 |
Fereshteh Sadeghi European Conference on Computer Vision (ECCV), 2012 In this paper we proposed a simple but efficient image representation for solving the scene classification problem. Our new representation combines the benefits of spatial pyramid representation using nonlinear feature coding and latent Support Vector Machine (LSVM) to train a set of Latent Pyramidal Regions (LPR). Each of our LPRs captures a discriminative characteristic of the scenes and is trained by searching over all possible sub-windows of the images in a latent SVM training procedure. The final response of the LPRs form a single feature vector which we call the LPR representation and can be used for the classification task. |
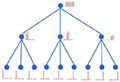 |
Conference on Computer Vision and Pattern Recognition (CVPR), 2013 Large-scale recognition problems with thousands of classes pose a particular challenge because applying the classifier requires more computation as the number of classes grows. The label tree model integrates classification with the traversal of the tree so that complexity grows logarithmically. We show how the parameters of the label tree can be found using maximum likelihood estimation. This new probabilistic learning technique produces a label tree with significantly improved recognition accuracy. |
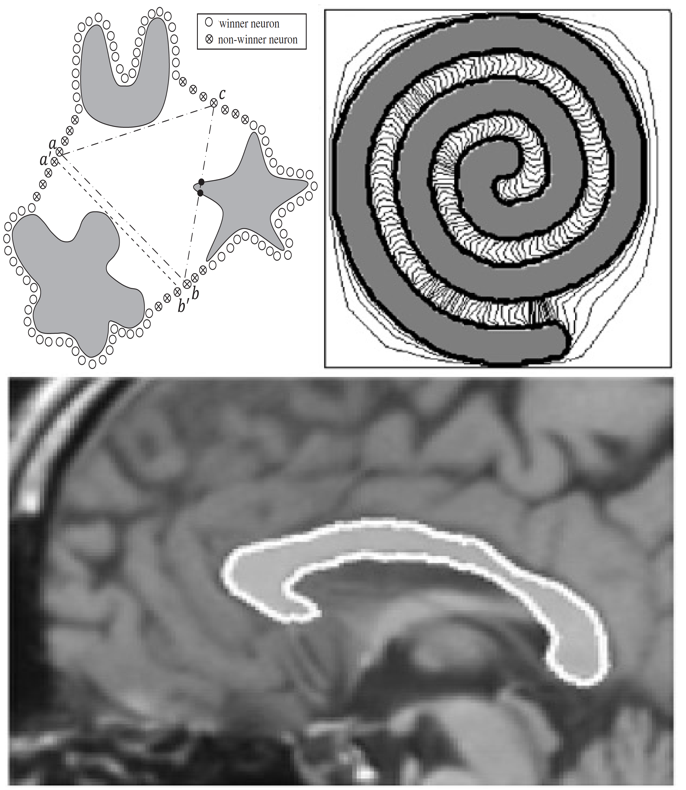 |
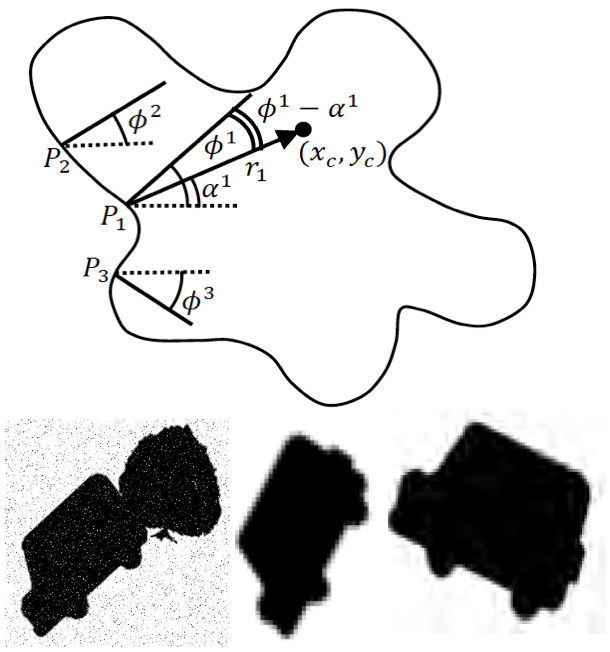
Fereshteh Sadeghi Pattern Recognition Letters, 2011 IEEE Int. Conf. on Control, Automation, Robotics and Vision, 2010 (earlier version) In this paper we build upon self organizing map neural networks to develope an active contour model. We extend the Batch SOM method (BSOM) by introducing three mechanisms of Conscience, Archiving and Mean-Movement and test on number of grayscale complicated shapes including medical images. |
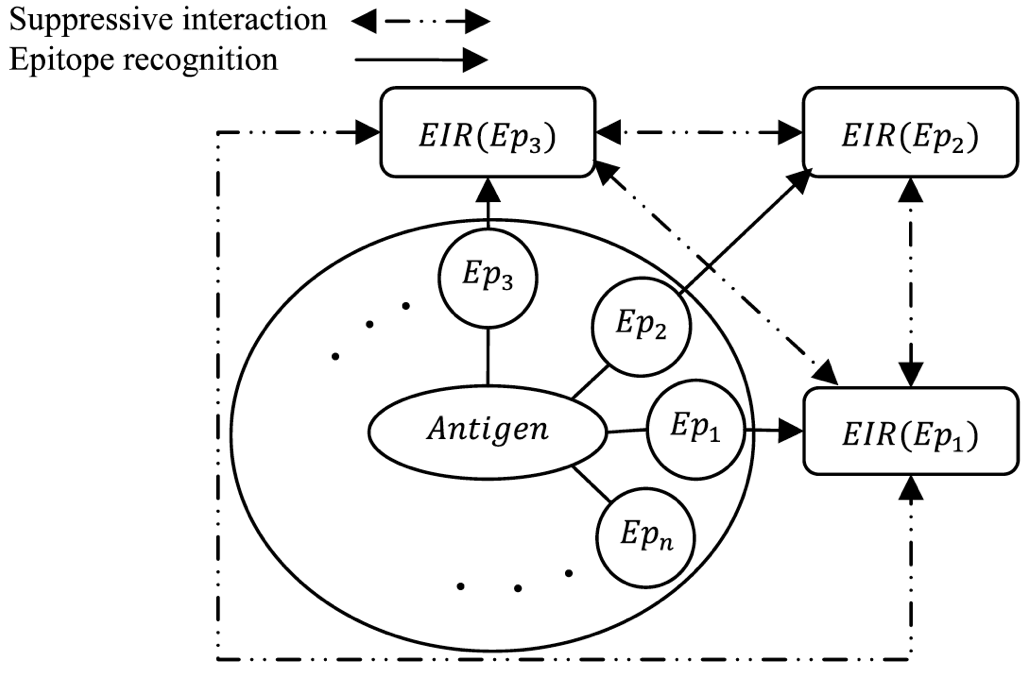 |
Neural Networks, 2009 International Joint Conference on Neural Networks, 2009 (earlier version) Inspired from natural immune system and Jerne theory of immune network, in this paper we propose a multi-epitopic immune network model for pattern recognition. The proposed model is hybridized with Learning Vector Quantization (LVQ) and fuzzy set theory to present a new supervised learning method. |
 |
International Conference on Fuzzy Systems, 2009 In this paper we propose a Generalized Hough Transform technique that can handle rotation, scale and noise. Our method builds upon funzzy theory and impoves the classic Hough Transform technique via fuzzy inference. |
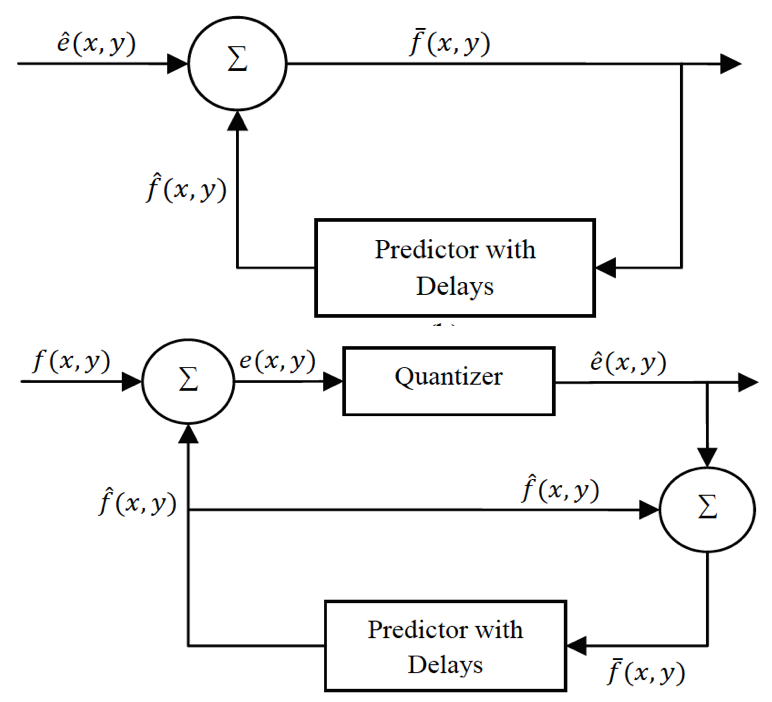 |
IEEE International Conference of Soft Computing and Pattern Recognition, 2009 In this paper a new steganography method based on predictive coding which employs Quantization Index Modulation(QIM) is proposed. Furthermore, a correction mechanism is proposed to preserve the histogram of the cover image and make it resistant against histogram-based attacks. |
 |
IEEE International Conference on Computer and Automation Engineering, 2009 This paper presents a new steganographic method based on predictive coding and embeds secret message in quantized error values via Quantization Index Modulation (QIM). The proposed method is superior to previous methods in that it can make a satisfying balance among the most concerned criteria in steganography which are imperceptibility, hiding capacity, compression ratio and robustness against attacks. |
|
| |
|
|
|
|
 ~ June. 2019 ~
~ June. 2019 ~ |
DIViS: Domain Invariant Visual Servoing |
Sim2Real Viewpoint Invariant Visual Servoing by Recurrent Control |
|
CAD2RL, Simulation Randomization (a.k.a. Domain Randomization) |
|
|
|
|
Program committee/Reviewer member ScienceRobotics AAAS, 2021 Robotics: Science and Systems (RSS), 2021, 2022, 2019 Conference on Robotic Learning (CoRL), 2022, 2021, 2020, 2019, 2018, 2017, 2018, 2019 IEEE Conference on Robotics and Automation (ICRA) , 2023, 2020, 2019, 2018, 2017 IEEE Conference on Intelligent Robots and Systems (IROS), 2017 IEEE Robotics and Automation Letters (RA-L) Workshop co-organizer Women in Robotics IV at Robotics: Science and Systems (RSS), 2018 |

|
Program committee/Reviewer member Conference on Computer Vision and Pattern Recognition (CVPR), 2020, 2019, 2018, 2017, 2016, 2015, 2014 International Conference on Computer Vision (ICCV), 2019, 2017 European Conference on Computer Vision (ECCV), 2020, 2018, 2016, 2014 Asian Conference on Computer Vision (ACCV), 2014, 2012 Winter Conference on Applications of Computer Vision (WACV), 2016, 2015 International Journal of Computer Vision (IJCV) |
|
|
Program committee/Reviewer member International Conference on Learning Representations (ICLR), 2020, 2019 Advances in Neural Information Processing Systems (NeurIPS), 2019, 2018 IEEE Trans. on Neural Networks and Learning Systems |
|
|
 source
source
|
Teaching Assistant and Guest Lecturer CSEP 573 - Winter 2016 CSE 473 - Autumn 2015 Search, Expectimax, CSP, MDP, Reinforcement Learning, Q-Learning, Uncertainty, Hidden Markov Models (HMMs), Baysian Networks (BNs), Naive Bayes, Perceptron, and fun PacMan game. Teaching Assistant and Guest Lecturer CSEP 546 - Spring 2016 Learning theory, Bayesian learning, Neural networks, Support vector machines, Clustering and dimensionality reduction, Dimensionality reduction (PCA), Model ensembles Instructor Vision Seminar , CSE 590v - Autumn 2015 GRAIL Seminar , CSE 591 - Winter 2016 |
|
|